![]() Slovo Triage se v posledních týdnech a měsících nejednou objevilo v médiích v souvislosti s koronavirem. Objevovalo se zejména na vrcholu nákazy v Evropě a označovalo jakousi prioritizaci pacientů, kterým měla být poskytnuta zdravotnická pomoc, když byly kapacity naplněny. Tento pojem však v podobném významu známe i v kyberbezpečnosti, kdy jde o prioritizaci řešení upozornění (alertů), které jsou výsledky různých detekčních metod.
Slovo Triage se v posledních týdnech a měsících nejednou objevilo v médiích v souvislosti s koronavirem. Objevovalo se zejména na vrcholu nákazy v Evropě a označovalo jakousi prioritizaci pacientů, kterým měla být poskytnuta zdravotnická pomoc, když byly kapacity naplněny. Tento pojem však v podobném významu známe i v kyberbezpečnosti, kdy jde o prioritizaci řešení upozornění (alertů), které jsou výsledky různých detekčních metod.
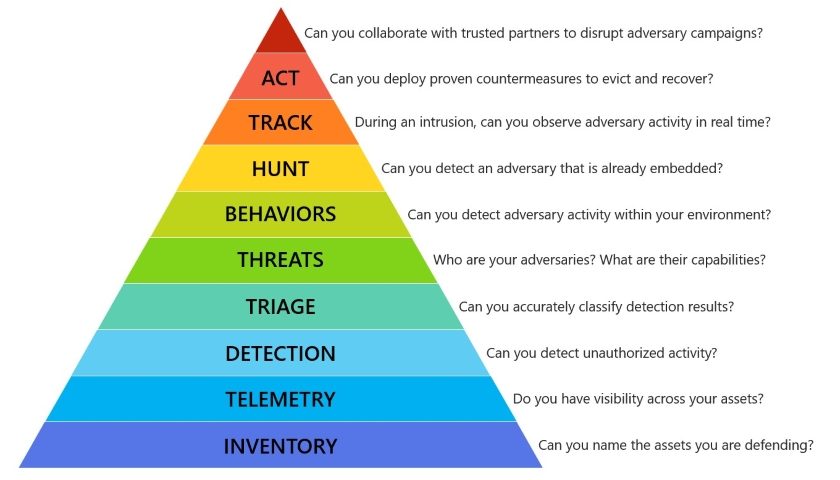
Pod tímto názvem nacházíme i další potřebu v hierarchii potřeb v kyberbezpečnosti. Po znalosti ochraňovaných aktiv a široké viditelnosti do dějů, které na nich probíhají se přes detekci neautorizovaných dějů dostáváme k potřebě správného vyhodnocení výsledků detekčních metod a jejich priorit.
Téma vyhodnocování a prioritizace jsem již částečně načal zejména v posledním článku z této série, který se zabýval ověřitelnosti a přesností detekčních metod. Ověřitelnost upozornění nám umožňuje znát, jak přesně daná detekční metoda funguje, a správně rozumět upozornění na výstupu dané detekční metody. Přesnost metody je zase ovlivňována pravdivostí těchto upozornění, která vychází právě z jejich vyhodnocení a rozhodnutí, zda jde o falešný poplach nebo důsledek bezpečnostního incidentu.
Prioritizace upozornění
Pro jednoduchost můžeme uvažovat ve standardním scénáři – logy, NetFlow, endpointová data se sbírají do SIEM, kde probíhá detekce, jejíž výsledky (upozornění, alerty) jsou následně vyhodnocovány SOC týmem. Upozornění bude standardně hodně a je logicky nutné určit, která z nich jsou nejzávažnější a podle toho jejich začít vyhodnocovat. Jako jediné objektivní kritérium pro prioritizaci vnímám důležitost dotčených aktiv, resp. předpokládaný dopad detekovaného bezpečnostního incidentu na činnost dané organizace. Z různých důvodů to však v praxi často nebývá.
Skutečná priorita upozornění je nutně subjektivní vlastnost, která i když je teoreticky definována hlavně z pohledu dopadu na činnost organizace, je v praxi ovlivňována dalšími dynamickými a často subjektivními faktory, jako počet upozornění vyžadujících prioritizaci, jiné upozornění týkající se stejného aktiva, očekávaná doba analýzy a řešení jednotlivých upozornění apod. Na základě subjektivní (i když do jisté míry formalizovatelné) kombinace různých faktorů, vznikne konečná priorita a upozornění se začne vyhodnocovat. Jednoduše řečeno, analytik se dle aktuálního souběhu relevantních faktorů „nějak“ rozhodně a vybere si upozornění, které začne vyhodnocovat.
Vyhodnocování upozornění
Úkolem analytika při vyhodnocování upozornění je zodpovědět 6 otázek – Kdo? Co? Kdy? Kde? Proč? Jak? (Z anglického 5W1H – Who? What? When? Where? Why? How?) – o detekovaném bezpečnostním incidentu. Následně by měl do hry vstoupit incident response tým, který odpovídá za reakci na bezpečnostní incident. Spolupráce s IR týmem nemusí být přesně nalajnovaná, spíše by se dalo říci, že probíhá v cyklech – analytik něco zjistí, odevzdá to incident response týmu, který si vyžádá další informace a tak dokola, dokud není incident vyřešen. Případně v procesu vyhodnocování zjistí, že jde o falešný poplach, což však zase musí dobře zdůvodnit.
Opomeňme na chvíli technické možnosti a nástroje a také úroveň zkušeností a znalostí u konkrétního analytika. Co je skutečným odrazem této potřeby vyhodnocení upozornění je rychlost a správnost – musíme na výše zmíněné otázky odpovědět správně a rychle. Jak toho však dosáhnout? Technické vybavení a znalosti jednotlivých analytiků určitě hrají svou roli, ale na čem vyhodnocování stojí a padá, je procesní stránka věci.
V praxi se na to používají tzv. runbooky nebo playbooky. Ty by měly v sobě obsahovat do jisté míry formalizované postupy, jak vyhodnotit jednotlivá upozornění, včetně toho, jaké technické nástroje použít, odkud čerpat dodatečné data, koho kontaktovat a pod. Nespornou výhodou runbooků je, že jsou deterministické – při stejném upozornění nám (teoreticky) vždy vyjde stejný výsledek. Co však správnost a rychlost?
Determinismus runbooků garantuje správné vyhodnocení. Runbooky vytvářejí zpravidla zkušenější analytici a asi nedává velmi smysl vytvořit runbook podle postupu, který neprodukuje správné výsledky. Čili pokud je postup analyticky správný a jsou použity správné nástroje, měl by vždy vyjít správný výsledek.
Co se týče rychlosti, runbooky, podle úrovně detailu v nich, do jisté míry odstraňují nutnost „myslet“, což snižuje šanci, že se analytik při vyhodnocování někde „zamotá“. Pokud je však runbook příliš specifický, může zas analytika zpomalit. Co však nejvíce ovlivňuje rychlost vyhodnocení je vhodná úroveň formálnosti, která umožňuje automatizaci celého vyhodnocení a jeho výrazné zrychlení, např. v systému SOAR, o kterém jsem psal v jednom z minulých článků.
Upozornění jsme tak dali v našem standardním scénáři správnou prioritu a protože máme kvalitní runbooky, dokázali jsme ho i rychle a správně vyhodnotit. V časové posloupnosti by měla asi následovat reakce na incident, ale ta je z pohledu hierarchie potřeb částečně pouze implicitním prodloužením Triage a částečně jí patří nejvyšší stupínky hierarchie.
Dalo by se říci, že jsme se dosud dívali zejména na svůj píseček – jaké aktiva chráníme, co se na nich děje a co z toho by se asi dít nemělo. V dalších částech se však podíváme ven – na potřeby související s cyber threat intelligence.
Dávid Kosť, Lead Security Analyst, AXENTA a.s.
Peter Jankovský, CTO, AXENTA a.s.
Obrázek: Matt Swan


