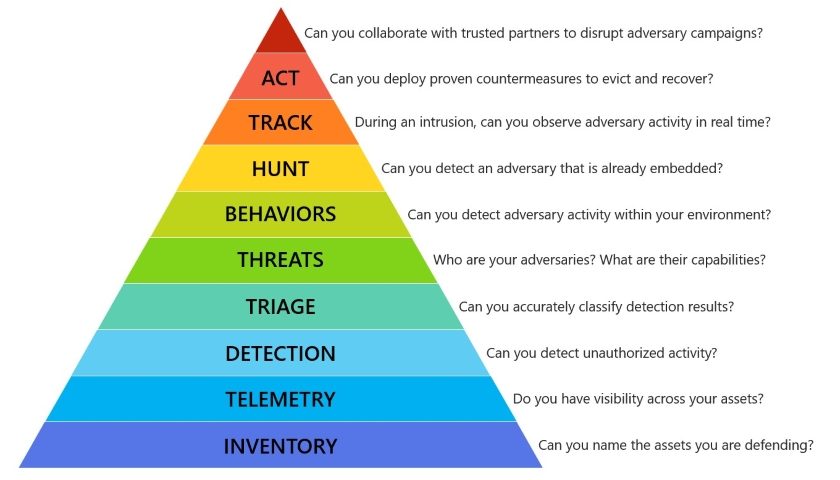
Minulou částí jsme začali rozebírat třetí stupínek kyberbezpečnostní hierarchie potřeb – potřebu detekce. Konkrétněji jsme se zabývali detekcí vzorů, které konkrétně popisují neautorizovanou činnost. Příkladem takových vzorů jsou např. AV signatury, IDS pravidla nebo korelace v standardních SIEM systémech.
![]() Hlavním problémem tohoto přístupu je velká specifičnost vzorů – odpovídají konkrétní operaci nebo ději a při změně útoku je nutné tento vzor upravit nebo vyrobit nový, což s sebou přináší netriviální časovou náročnost a také nutnost určité expertní znalosti v přípravě detekčních metod. Tento problém se s proměnlivým úspěchem snaží adresovat různé projekty a nástroje, jako je např. MITRE ATT & CK, Sigma nebo YARA. Stále však jde svým způsobem o přístup blacklisting – snažit se popsat všechny možné neautorizované operace. Opačný přístup, whitelisting, vidíme u druhého typu detekcí – detekce anomálií, kde základní činností je popsání standardního nebo žádaného stavu a detekční metody se soustředí na jakékoliv odchylky.
Hlavním problémem tohoto přístupu je velká specifičnost vzorů – odpovídají konkrétní operaci nebo ději a při změně útoku je nutné tento vzor upravit nebo vyrobit nový, což s sebou přináší netriviální časovou náročnost a také nutnost určité expertní znalosti v přípravě detekčních metod. Tento problém se s proměnlivým úspěchem snaží adresovat různé projekty a nástroje, jako je např. MITRE ATT & CK, Sigma nebo YARA. Stále však jde svým způsobem o přístup blacklisting – snažit se popsat všechny možné neautorizované operace. Opačný přístup, whitelisting, vidíme u druhého typu detekcí – detekce anomálií, kde základní činností je popsání standardního nebo žádaného stavu a detekční metody se soustředí na jakékoliv odchylky.
Detekce anomálií
Tento přístup k detekci není nový, první detekce založené na statistických metodách sahají desítky let dozadu, nicméně rychlý vývoj v oblasti zpracování velkých dat a strojového učení měl za následek jejich velké rozšíření v posledních letech. Pojem anomálie asi nemusím vysvětlovat, co je podstatné, je spíše způsob určení toho, co je normální. Dlouhou dobu na to byly využívány standardní statistické metody s poměrně typickou aplikací pro detekci síťových anomálii – objem komunikace, délka komunikace, využití portů a různé další metriky a jejich kombinace.
Typickým jednoduchým příkladem na ilustraci může být například detekce anomálií v objemu přenesených dat nějaké IP adresy za 15 minut. Pokud objem stoupne oproti předchozím 15 minutám o více než 1000%, je to anomálie. Vidíme hned minimálně 1 problém – co se stane, když člověk přijde ráno do práce, zapne počítač a najednou přirozeně přenese obrovské množství dat oproti 15 minutám, když ještě v práci nebyl. Mohli bychom to vyřešit tak, že metoda bude fungovat pouze v nějakém čase. Co ale s počítači, které jsou využívány v jiných časech? Možná použijeme průměr za delší čas? Takto můžeme pokračovat donekonečna. Co je horší, každá taková eventualita, se kterou musíme počítat, nás stojí další kousek výkonu a času.
Pokud jsme při detekcích vzorů říkali, že „přesně toto je špatné a když to najdeš, tak mě upozorni“, tady říkáme, že „takto je to obecně normální, vše co je jinak je zlé … ale vlastně toto není špatně, a vlastně ani toto … a upozorni mě, až když zkontroluješ těchto 20 výjimek „. Snažím se říct, že navrhnout dobrou detekční metodu založenou na statistických metodách může být mnohem náročnější než v případě vzorů.
Pomoc přišla s rozvojem analýzy velkých dat a strojového učení, který byl možný díky rostoucímu výkonu počítačů. Neřekl bych, že jsme najednou vyřešili všechny problémy detekce anomálií, ale dokázali jsme se posunout od různých statistických metod ke kvalitativní analýze, dokážeme sledovat mnohem více faktorů najednou a rychleji jejich vyhodnocovat. Takové detekční metody nacházíme hlavně v různých User and / or Entity Behavior Analysis (UBA, EBA, UEBA) řešeních, které se snaží namodelovat nad obrovským množstvím dat, jak vypadají činnosti daného uživatele nebo zařízení normálně a různé odchylky od tohoto normálu představují anomálie. Tyto nástroje nevyhodnocují už jen počty a statistiku, ale dokážou vidět i „dovnitř“, dokáží zpracovat obsah komunikace, spuštěné programy, stromy procesů apod.
S tím však přicházejí další nové problémy řešeny v oblasti strojového učení, zejména co se týká získávání kvalitních dat, návrhu a testování modelů strojového učení, či ověřitelnosti výsledných detekcí.
Právě ověřitelnost však není problémem jen u detekce anomálií, ale spolu s korektností a dalšími obecnými vlastnostmi detekcí, se dotýká i detekce vzorů, o čem si více řekneme v následujícím čísle.
Dávid Kosť, Lead Security Analyst, Axenta a.s.
Peter Jankovský, CTO, Axenta a.s.
Další články společnosti Axenta:
Hierarchie potřeb v kyberbezpečnosti – 1.část
Hierarchie potřeb v kyberbezpečnosti – 2. část
Hierarchie potřeb v kyberbezpečnosti – 3. část
Hierarchie potřeb v kyberbezpečnosti – 4.část
Jak se nenechat vydírat ransomwarem
Hierarchie potřeb v kyberbezpečnosti – 5. část
Hierarchie potřeb v kyberbezpečnosti – 7. část
V Brně bylo otevřeno první Junior Centrum Excelence pro kybernetickou bezpečnost v ČR
Obrázek: Matt Swann


